20 Years of Messy Data: How I'm Finally Fixing My last.fm Scrobble History


I've been scrobbling (tracking my music plays to Last.fm) since April 2006. That's nearly 150,000 plays logged over two decades. And while I've known for most of that time that my data was a mess, it was just too difficult to correct it all.
Why does this even matter? Last.fm is, at its core, a record of your musical listening life. It's the thing that tells you what your years in music actually looked like, what artists you kept coming back to, how your taste evolved over time. It's Spotify Wrapped, but for everything, and forever. And for someone like me, someone who loves both music and data about music, those charts and graphs and year-end reports aren't just fun, they're meaningful.
But only if they're accurate.
What if your end-of-year report showed half your plays for your favorite artist split across three different spellings of their name? What if your top song was actually your top three songs, fragmented across "Album Version," "Remastered," and "no album"? The reports still generate. The charts still look pretty. But you know they're wrong. And once you know that, they stop meaning anything.
So I built a tool to surface these data issues so they could be corrected.
Here's a walkthrough of how the development came about and how the tool works:
Let me explain how I got here...
The Problems I Couldn't Find
Last.fm is great at tracking that you listened to something. It's terrible at keeping that data clean.
Over these last 20 years I have scrobbled from dozens of different devices - PCs, Macs, iPods and phones, starting with my own ripped and tagged MP3s. Then I moved to streaming and a litany of services - Rhapsody, Yahoo Launch, Yahoo Unlimited, Pandora, Slacker, Rdio, Spotify, Tidal, YouTube, Deezer and probably many more that have since come and gone. It was inevitable that my library had accumulated invisible chaos:
- "The Allman Brothers Band" vs "Allman Brothers Band" vs "The Allman Brothers Band " (with a hidden space) - all treated by last.fm as unique artists
- "Abbey Road" vs "Abbey Road (Remastered)" vs "Abbey Road (Super Deluxe Edition)" - all the same album, split across three entries
- Plays scattered across Greatest Hits compilations instead of the desired original releases
- Tracks scrobbled without any album connection at all
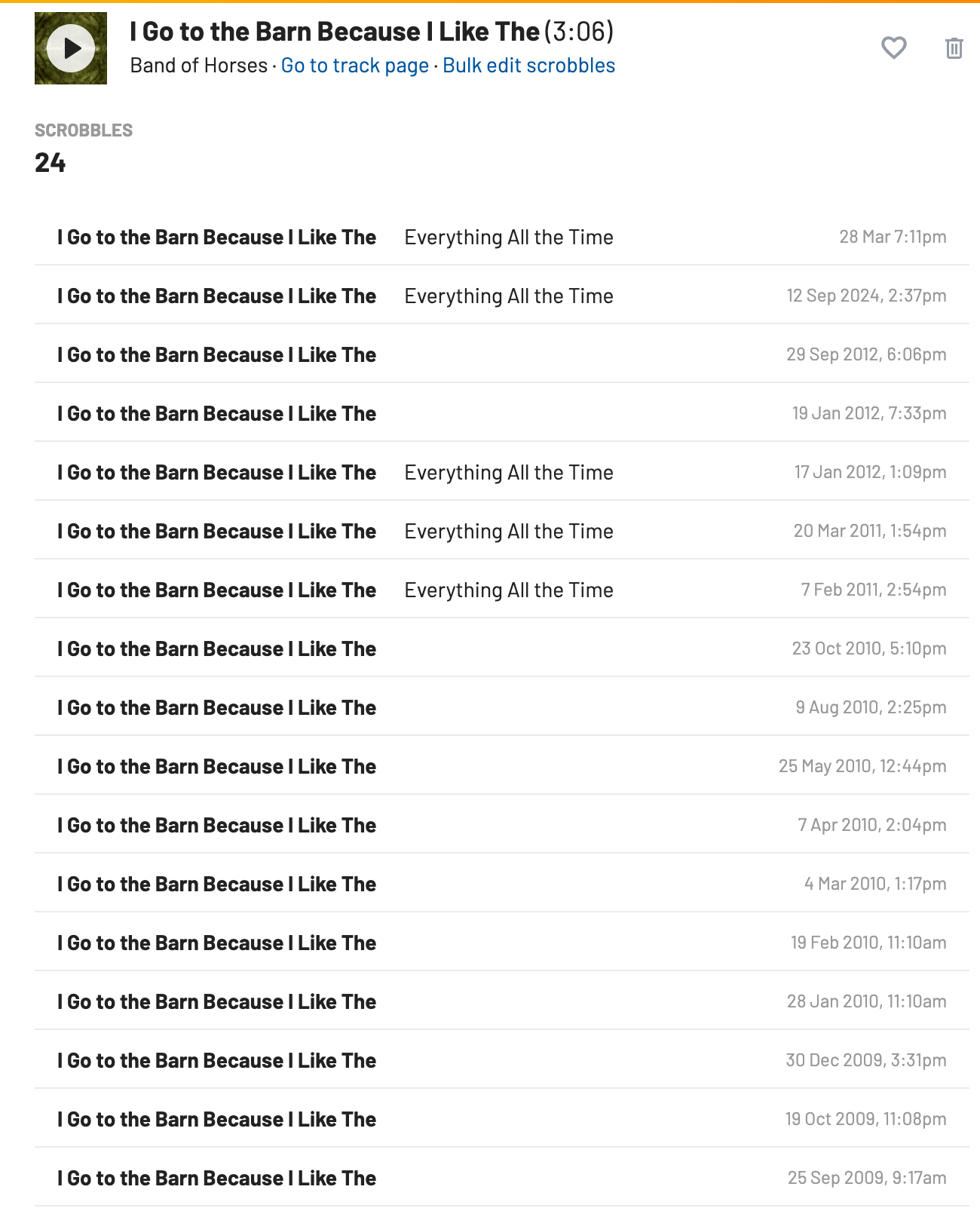
I knew these problems existed. I'd stumble across them occasionally - notice a weird duplicate, spot a misspelling or an odd variation of an album or track. But actually finding them systematically? Impossible. Last.fm gives you no way to surface data quality issues. You'd have to manually check thousands of entries, hoping to spot what's wrong.
I went looking for a tool that could help. Nothing existed. Plenty of services would show you your top artists or generate pretty charts, but nothing that said "hey, you've got issues in your library - here they are."
So, in collaboration with Anthropic's Claude AI, I built one.
The scope of the problem turned out to be worse than I imagined. When I finally ran my data through the tool, I found 77 artist variations, 488 album issues, over 600 track variations, and 179 unique tracks by The Beatles alone that were missing any associated album. That last one - tracks with no album - was essentially impossible to locate directly in Last.fm's interface. Now I had a list.
The Approach: Document the Problem First
I'm not a developer. I can't write code. But I've spent years solving technical problems for myself and clients, and I've learned something: the quality of your solution depends entirely on how well you understand and communicate the problem.
Before I wrote a single line of code (or rather, before I asked Claude to write any code), I spent a couple of days documenting exactly what problem I was trying to solve:
What data quality issues exist in Last.fm scrobbles?
- Artist name variations (The Beatles vs Beatles)
- Album variations (remasters, deluxe editions, regional differences)
- Track variations (live versions, remasters, re-recordings)
- Missing album data
- Compilations fragmenting play counts
- Invisible character differences (non-breaking spaces, Unicode)
What does the available data look like?
- Last.fm doesn't provide a native export but there are third-party tools like lastfmstats.com that can export CSV files
- The data export includes Artist, Album, Track, Scrobble Date, and sometimes MusicBrainz IDs
What should the tool actually do?
- Surface issues, not fix them automatically. Users can and should own and control their own data
- Sort by impact so the biggest problems can be fixed first
- Link directly to the identified item on Last.fm so users can make the edits and corrections
- Run entirely in the browser (no uploading listening history to some server)
What should it NOT do?
- Make assumptions about what's "correct"
- Require any technical knowledge to use
- Need confusing or complicated installation or setup
This wasn't just busywork. This document became the blueprint. When I started my project with Claude, I wasn't saying "build me a Last.fm tool" - I was saying "here's exactly what's broken, here's what the data looks like, here's what success looks like, here's what's out of scope."
Building It: Three Weeks from Concept to Public Release
With the problem clearly documented, the actual building went amazingly fast.
Week 1: Core Detection
The first working version we built could detect artist variations, album variations, and track variations. It wasn't very pretty but it was functional. I loaded my own export and the scope of the problem finally became clear - nearly 20 years of accumulated data quality issues, now surfaced and sortable.
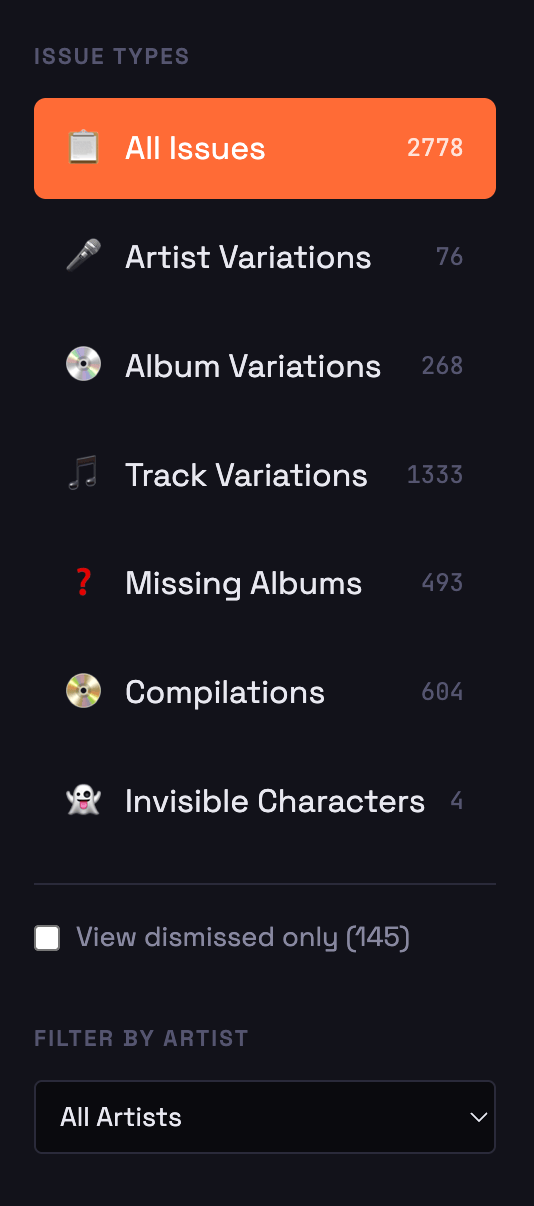
Week 2: Polish and Additional Detection
Based on what I found in my own data, we added:
- Missing album detection (tracks scrobbled without album info) - this was huge!
- Compilation detection (plays on "Greatest Hits" type releases that could be reassigned)
- Invisible character detection (the sneakiest problem - names of artists and such that appear identical but contain hidden Unicode characters)
- Direct links to Last.fm for each issue
- A cleaner interface with sorting and filtering
Week 3: Public Release and Iteration
I announced it in the Last.fm subreddit and within a day it had 100+ upvotes, dozens of thank you comments, and people were actually using it. More importantly, they were giving me useful feedback or reporting issues:
- "My file won't load" → Found a bug where certain artist names broke the parser
- "Can you detect Unicode apostrophes?" → Added smart quote detection (turns out MusicBrainz uses Unicode apostrophes while most services use ASCII - creating invisible duplicates)
And from using the tool extensively myself, I realized something: with 179 Beatles tracks to fix, I wasn't going to do that in one sitting. I needed a way to mark progress, dismiss items I'd dealt with, and most importantly, pick up where I left off next time. So we built that too, dismiss functionality with persistence, so the tool remembers your progress when you come back.
Each iteration made the tool more useful. The version that exists today is significantly better than what I released two weeks ago.
What I Learned
1. The planning document was the actual work.
The coding took hours. The thinking took days. And that's the right ratio. I've seen projects fail because someone jumped straight to building without understanding what they were building or why. Because I was clear and knowledgeable about the problem, the faster and better the solution came together.
2. AI is a multiplier, not a replacement.
I couldn't have written this code myself. But Claude couldn't have built this tool without my 20 years of context about what makes scrobble data messy, how Last.fm users actually think about their libraries, and what workflow would actually be useful. The collaboration worked because I brought knowledge and clear requirements; the AI brought the implementation skills.
3. Ship it ugly, then iterate.
The first public version was missing features I wanted but I shipped it anyway. Even though it was essentially a "proof of concept" it was already useful and I wanted to get it in to the hands of those who could, and would, use it. The feedback from real users was more valuable than another week of me trying to anticipate what they might need.
4. Solve your own problem first.
I built this because I was annoyed. That annoyance gave me the motivation to finish it and the knowledge to get the details right. If you're thinking about building something, start with a problem you personally have and actually care about solving.
What's Next?
This project isn't done. The current version surfaces problems and helps you track your progress fixing them, but you still have to figure out what is the correct variation. Is it Derek and the Dominos or Derek & the Dominos? Was this song by Elvis Costello, or Elvis Costello and the Attractions (or is it Elvis Costello & the Attractions) or maybe it was Elvis Costello and the Imposters?
So the next phase involves learning how the Last.fm API and MusicBrainz database work together, understanding the data structures well enough to suggest corrections or at least make it easy to research and find the right name or attribution. That's new territory for me, but that's the point (and the fun!) - each project is an opportunity to learn something I didn't know before and expand what's possible next time.
Working With Claude
As much as I have always wanted to do so, I couldn't have built this on my own. I'm technically minded and proficient and I understand the systems, but I'm not a developer. What I could do is clearly document what needed to exist and why. The combination of my knowledge and problem definition skills, with Claude's coding ability, is what made this process successful, and why we have a tool that people are using.
The collaboration worked because:
- I spent days documenting the problem before Claude wrote any code
- I have 20 years of experience and context about what makes scrobble data messy
- I knew what workflow would actually be useful for users who would use this tool
- Claude brought the technical implementation and coding skills
- We iterated based on real feedback from actual users, like me.
To me, this is what effective AI collaboration looks like, and this is exactly how I treated this process. We chatted, I asked if things were possible and how much complexity features would add. I created a process to define scope of each build and broke the project down in to manageable phases. I had the experience and the expertise, Claude just helped bring that vision to life.
What I built - The Scrobble Analyzer Tool
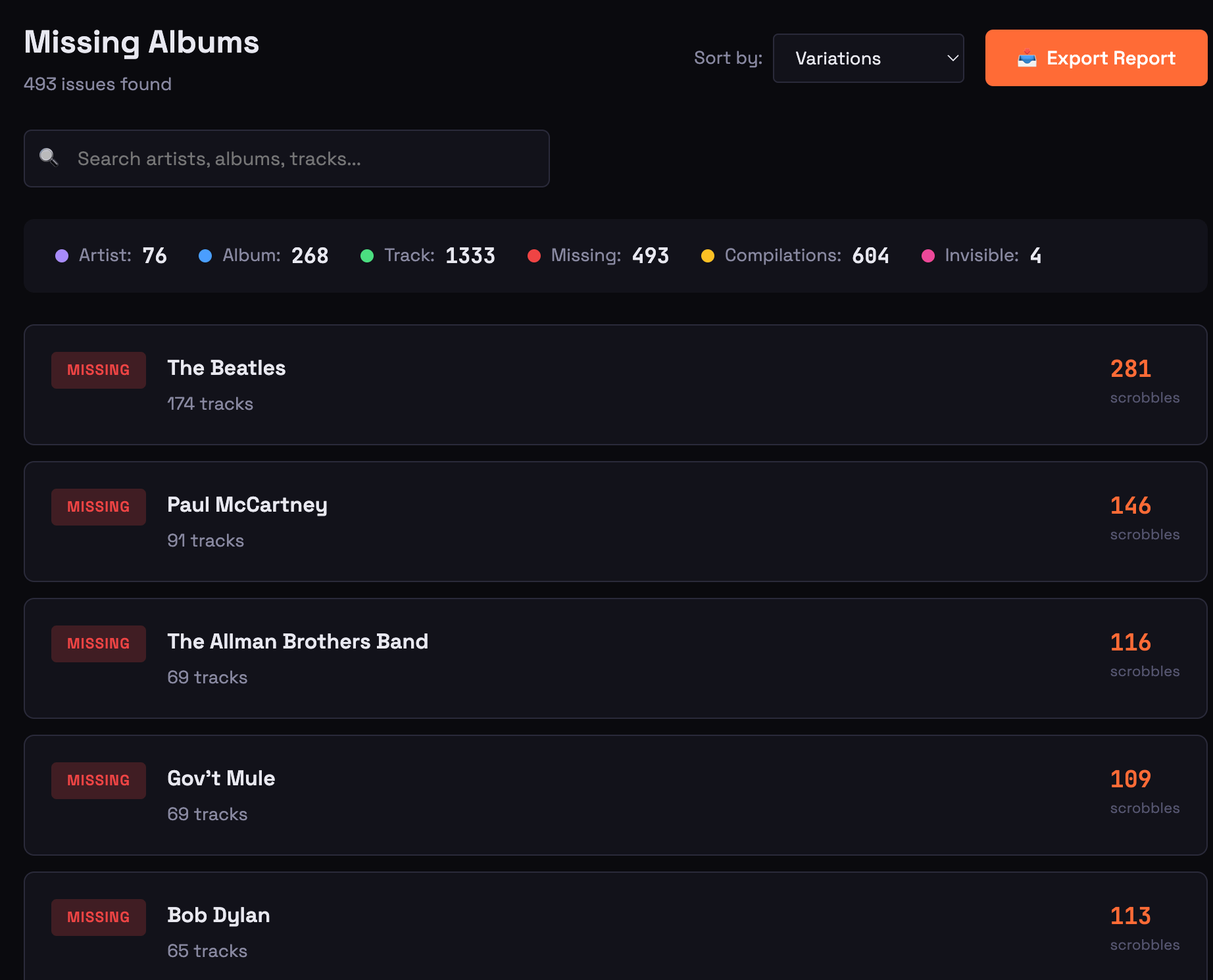
Scrobble Analyzer is free to use, open source, and it runs entirely in your browser:
Export your data from lastfmstats.com, drop in the CSV, and see what's hiding in your library. I bet you will be surprised.
I Figured It Out
It is what I do. And I'm good at it.
Not just tools for Last.fm - but this process of identifying problems, documenting them clearly, finding or building solutions, and then testing and iterating until they work as required.
If you've got a technical annoyance you've been living with:
- something that should work better but doesn't - "Why can't I just do this?"
- a manual process that's eating your time - "There has to be an easier way to do this?"
- data that's messier than it should be or needs to be connected to something else - "How can I get my CRM to talk to our email list?"
Contact me - I can probably help you figure it out.
This post is part of Figure It Out With Scott, where I document how I solve technical problems and annoyances. Subscribe for updates or watch on YouTube.